Script para pasar código Python a HTML
Hola. En este artículo vamos a crear un script para pasar código fuente Python (.py) a formato HTML (y de esta manera mostrar dicho código en una página web). Además vamos a darle coloración al código Python. Debe de haber formas más simples, sin duda, de resolver este tipo de problemáticas, ... a mí se me ha ocurrido esta.
Como siempre, el fichero .py que contiene el script se puede obtener del repositorio de este blog, en:
https://sites.google.com/site/elviajedelnavegante/
El fichero se llama mi_tokenize.zip, el cual contiene el script mi_tokenize.py.
En este problema no se ha utilizado programación orientada a objetos, esto es, no se implementa ninguna clase. Todo se resuelve con programación imperativa (mediante funciones).
Al grano...
El funcionamiento es sencillo, en términos generales. De lo que se trata es que, a partir de un fichero de código fuente Python, se genera otro (con extensión html) con código HTML, que representa el código Python formateado (con indentación y coloreado de código).
Un ejemplo sería el siguiente:
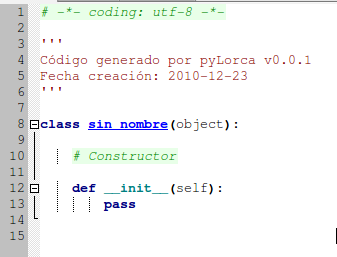
La captura de arriba es del Stani's Python Editor. Abajo nos encontramos el mismo código, formateado en HTML y coloreado, en Firefox.








Y la función para incluir la cabecera y pie del documento de la página web:

Como siempre, el fichero .py que contiene el script se puede obtener del repositorio de este blog, en:
https://sites.google.com/site/elviajedelnavegante/
El fichero se llama mi_tokenize.zip, el cual contiene el script mi_tokenize.py.
En este problema no se ha utilizado programación orientada a objetos, esto es, no se implementa ninguna clase. Todo se resuelve con programación imperativa (mediante funciones).
Al grano...
El funcionamiento es sencillo, en términos generales. De lo que se trata es que, a partir de un fichero de código fuente Python, se genera otro (con extensión html) con código HTML, que representa el código Python formateado (con indentación y coloreado de código).
Un ejemplo sería el siguiente:
La captura de arriba es del Stani's Python Editor. Abajo nos encontramos el mismo código, formateado en HTML y coloreado, en Firefox.

¿Cómo enfocar el problema?
Pasar código Python a html es casi trivial. Únicamente hay que abrir un fichero .py, leerlo, crear otro fichero con una cabecera html, incluir dicho código Python y cerrar el html. Listo, ya tenemos el código en una página web.
El verdadero problema es el coloreado del código, ya que se tiene que identificar los diferentes bloques de código a los que se quieren dar color. En nuestro caso, daremos color a los comentarios, a las cadenas y a las palabras clave de la versión que utilicemos de Python.
¿Cómo hacerlo? Mediante los módulos cStringIO y tokenize, que se pueden encontrar en cualquier distribución de Python.
cStringIO sirve para crear, a partir de una cadena, un buffer de cadena. tokenize es el módulo que nos permite analizar código Python e identificar componentes del mismo (comentarios, cadenas, etc) a partir de un buffer de cadena. Mejor lo vemos con los pasos que debe de dar nuestro script:
1) Cargamos en memoria un fichero .py con el método read() de open.
2) Mediante cStringIO creamos un fichero en memoria ó buffer de cadena, el cual es necesario para utilizar el tokenize. En realidad esto sirve para iterar, línea a línea sobre una cadena con varias líneas (con saltos de línea). Por ejemplo:
import cStringIO
cadena = '''
Este es un ejemplo
de la potencia del
módulo cStringIO
'''
texto = cStringIO.StringIO(cadena)
for i in texto: print i
Devuelve:
Este es un ejemplo
de la potencia del
módulo cStringIO
3) Mediante tokenize, y a partir del buffer de cadena creado en el paso anterior, podemos obtener los token (elementos de código), iterando sobre ellos, e identificando los elementos de código Python.
En la documentación de Python tenéis una explicación muy buena (en inglés) de estos dos módulos:
Puff!!! Una explicación algo extraña. Veámoslo con un ejemplo. Imaginemos que hemos cargado mediante el método read() de open un fichero con código Python con el siguiente contenido:
# -*- coding: utf-8 -*-
# Código Python.
for i in range(0,5):
print "Número ", i
Mediante los pasos anteriores vamos a identificar los elementos del código, a saber, comentarios, palabras clave y cadenas. El código que haría esta operación podría ser el siguiente:
# Creamos buffer de cadena.
texto = cStringIO.StringIO(cadena)
# Creamos tokens.
tokens = tokenize.generate_tokens(texto.readline)
for a,b,c,d,_ in tokens:
if a == tokenize.STRING:
print "Cadena: %s en posición [%s,%s]" %( b,c,d)
if a == tokenize.NAME and b in keyword.kwlist:
print "Palabra clave: %s en posición [%s,%s]" % (b,c,d)
if a == tokenize.COMMENT:
print "Comentario: %s en posición [%s,%s]" % (b,c,d)
Dando como resultado:
Comentario: # -*- coding: utf-8 -*- en posición [(1, 0),(1, 23)]
Comentario: # Código Python. en posición [(2, 0),(2, 17)]
Palabra clave: for en posición [(3, 0),(3, 3)]
Palabra clave: in en posición [(3, 6),(3, 8)]
Palabra clave: print en posición [(4, 2),(4, 7)]
Cadena: "Número " en posición [(4, 8),(4, 18)]
Por tanto, mediante el módulo tokenize podemos identificar todos los elementos de los que se compone un código Python. La idea fundamental es esta. Aparte, mediante operaciones de transformación entre listas y cadenas, y demás operaciones se llega al resultado esperado.
¿Y cómo se colorea el texto? Pues mediante código HTML del tipo:
Así el otro hándicap es que a partir de las coordenadas de los elementos de código a colorear hay que insertar código HTML.
El script mi_tokenize.py
Tal como antes se ha comentado, el lector puede obtener el código de este script en el repositorio de El viaje del navegante. Aquí se presentan capturas de pantalla del código, debido principalmente a que se utiliza sintaxis html en el código Python, y no mezclar cosas.
Módulos que se cargan y estructuras que se definen:
Importamos los módulos necesarios y creamos un diccionario para colorear los elementos de código Python.
El código principal que ejecuta el script:
Podemos observar que el script pide dos argumentos para funcionar, el primero el fichero Python y el segundo el nombre del fichero html que se generará (se le da extensión .html si esta se omite) . A continuación llamamos a la función cargar_fichero que devuelve, mediante read() una cadena con el contenido del fichero. Finalmente, mediante la función tokenizar_codigo se crea una cadena con sintaxis html y Python, que se guarda en el fichero identificado por f_html_nombre.
Función para cargar el fichero .py:
Darse cuenta que reemplazamos ciertos caracteres especiales en html.
La función que analiza el código creando una cadena con html y código Python es la siguiente:
Esta función podría haberse escrito de otra forma, para ahorrar código, pero me ha parecido más pedagógico realizarlo de esta forma. Como se puede observar se utilizan cStringIO y tokenize. Devuelve una cadena con código html. Esta última función utiliza dos funciones auxiliares, a saber:
La función para insertar los elementos de html:
Y la función para incluir la cabecera y pie del documento de la página web:
Pero como no es lo mismo andar el camino que conocer el camino, es mejor probar el script. El lector puede pensar que sería mucho mejor utilizar CSS para estos menesteres, y en cierta manera, es verdad, pero no es objetivo de este post hacer un tratado sobre web y CSS. Lo verdaderamente importante es el parseo de código Python y el tratamiento de cadenas.
Se insta al lector a mejorar el código.
Saludos.


Dos cosas:
ResponderEliminar- en windows casca el os.path.realpath (\\)
- creo que te has liado con el cierre del texto en def codigo_html y % nombre. Casca también.
Solucionados los dos incidentes tira bien.
Gracias
Borde
elbordeinformatico.wordpress.com
Hola anónimo, buenas noches. Este script lo he probado en Linux, con Python 2.6.6. Gracias por molestarte en probar el código, te lo agradezco. A ver, lo de Windows, en principio el módulo os no debe de fallar, y si lo hace la verdad que no se porqué puede ser, aquí me pillas (y no me refiero a las \\ de Linux). Con respecto a lo del def codigo_html % nombre, a mi no me falla, ni en Windows ni en Linux, así que no se muy bien al fallo que comentas. Está hecho a posta, de esa manera, por si quería pasar el nombre del fichero .py, pero al final no lo he hecho. No se muy bien el error que te da.
ResponderEliminarLo he probado todo en Windows XP SP3, y a mi no me da problemas.
Gracias por ayudarme y problarlo. Un saludo.
no podias hacerlo un poquito mas complicado :D
ResponderEliminary tú anónimo, no puedes ser un poco más borde?. Gracias Angel Luis por el post
ResponderEliminar