Traspasar una base de datos de FireBird a SQLServer con Python
Hola. Hace unas semanas escribí un post para poder traspasar una base de datos alojada en un SGBD Firebird a una nueva base de datos en un SGBD de MySQL. Pues bien, ahora toca cambiar el destino, esto es, un SQLServer.
En este post vamos a ver cómo traspasar una base de datos, ubicada en un sistema gestor de bases de datos FireBird, a una nueva base de datos, ubicada en sistema gestor de bases de datos Microsoft SQLServer 2008 Express Edition.
Antecedentes
El origen será una base de datos FireBird con los siguientes atributos:
 (Esta información la he obtenido con FlameRobin, que es un sistema de administración para sistemas gestores de bases de datos FireBird, gratuito.)
(Esta información la he obtenido con FlameRobin, que es un sistema de administración para sistemas gestores de bases de datos FireBird, gratuito.)
Primer intento de traspaso
SQLServer 2008 Express Edition tiene una herramienta de exportación/importación de datos:
 NOTA: Decir que en esta versión Express no está disponible Integration Services, en donde se realizan tareas de ETL (carga de datos). Es por ello que no la he podido utilizar, aunque aparezca en el menú de la captura.
NOTA: Decir que en esta versión Express no está disponible Integration Services, en donde se realizan tareas de ETL (carga de datos). Es por ello que no la he podido utilizar, aunque aparezca en el menú de la captura.
Previamente a este paso he realizado un análisis de datos de los campos del origen, ya que no concuerdan con destino en algunos casos, y en otros no es posible asignar ciertos datos a SQLServer. Por ejemplo, la base de datos FireBird del origen (de aquí en adelante llamada origen) tiene tipos de datos Blob subtype que no tienen correspondencia con SQLServer, con lo que en el destino de la base de datos de Microsoft (destino de aquí en adelante) lo cambio por text ó ntext. Otro problema, por ejemplo, es que las tablas del origen admiten varios tipos de datos TimeStamp por tabla y en destino por cada tabla solo puede haber un TimeStamp. También hay problemas con algunas codificaciones de fechas. Aquí el destino responde bien, ya que SQLServer 2008 hace un tratamiento excelente de fechas (date) y tiempo (time), y datetime por supuesto. Muy interesante. Aquí Microsoft ha hecho un buen trabajo.
Después de un análisis de datos, en donde cambio ciertos tipos de datos, comienzo el traspaso. Las tablas más pequeñas las traspasa sin problemas, como podemos ver en la imagen:
 El problema reside en las tablas maestras, con un gran número de columnas (creo que el que diseñó la aplicación del origen no sabía mucho de normalización de bases de datos). El error que me da en las tablas se repite constantemente y es del tipo siguiente:
El problema reside en las tablas maestras, con un gran número de columnas (creo que el que diseñó la aplicación del origen no sabía mucho de normalización de bases de datos). El error que me da en las tablas se repite constantemente y es del tipo siguiente:
 Tanto al hacer click en “Editar asignaciones” como en “Siguiente”, me da este error:
Tanto al hacer click en “Editar asignaciones” como en “Siguiente”, me da este error:
 Este error parece ser que indica que no puede recorrer la tabla porque el puntero se sale del rango al recorrerla. Intento buscar más información sobre el error (que me da el propio asistente):
Este error parece ser que indica que no puede recorrer la tabla porque el puntero se sale del rango al recorrerla. Intento buscar más información sobre el error (que me da el propio asistente):
 Según parece no puede cargar el grid (vamos, poblar la rejilla, o como pone en el mensaje, que no puede populate).
Según parece no puede cargar el grid (vamos, poblar la rejilla, o como pone en el mensaje, que no puede populate).
He buscado en Internet sobre este error. No encuentro nada que me sirva (primeros sudores fríos bajan por la mejilla).
Busco en Internet soluciones para traspasar datos específicamente desde este origen al destino dado. Hay varias opciones, pero todas de pago (cosa que no me puedo permitir) y permiten pasar unas pocas filas o no hacen todo el traspaso, como ESF Database Migration Toolkit, DBConvert for Firebird and MSSQL ó Full Convert Enterprise, Pasan 2 horas… solución… scripts Python.
Solución: Scripts Python
Hace unos días escribí un artículo sobre traspasar datos entre una FireBird y MySQL, entonces, ¿por qué no para SQLServer? Es más, tengo cierta libertad para el uso de herramientas que me ayuden a realizar el trabajo. Y el jefe quiere resultados, da igual como los obtengas (bueno, a lo mejor aquí me he pasado un poco), pero hay que dar resultados con el menor coste posible.
Lo que voy a hacer es modificar el código del script del anterior artículo, para adecuarlo al destino actual. Decir que hay que realizar modificaciones, sobretodo con respecto a los tipos de datos de los campos (tanto en el origen como en el destino). Además, ahora también se pasarán los índices de las tablas (con un pequeño truco), cosa que en el anterior post no se hacía.
¿Por dónde empezar? (Conexiones con FireBird y SQLServer 2008.)
Normalmente, salvo que seas holandés, por el principio. Lo primero, ¿cómo me conecto con el origen (FireBird)? Mediante el módulo KinterbasDB. ¿Cómo conectarse con el destino (SQLServer)? Aquí había dos opciones. La primera, el módulo pymssql. Problema: permite conectarte a SQLServer 2000, pero parece que no le gusta demasiado SQLServer 2008, así que esta opción no me sirve. Segunda, conexión por ODBC. Para ello utilizo pyodbc. Así que me creo una conexión ODBC en el Administrador de Orígenes de Datos ODBC de Windows, y luego con pyodbc creo dicha conexión en el script Python. ¡¡¡Funciona!!!. Pues me quedo con esta opción.
Composición del proyecto
¿De qué se compone mi proyecto de traspaso? De los siguientes ficheros:
traspaso.py: Fichero donde reside el menú principal para controlar las diferentes partes del traspaso de datos. Desde aquí se llaman a los demás módulos y ficheros fuente. Para ejecutar nuestra aplicación tendremos que poner python traspaso.py. Nuestra aplicación tendrá más o menos este aspecto, en IDLE:
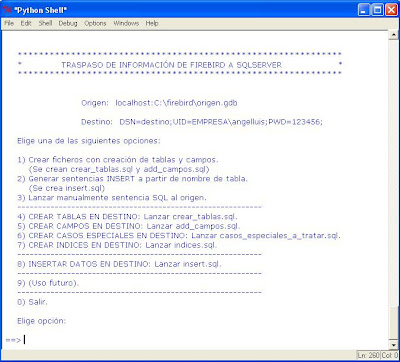
crear_tablas.py: Módulo para crear los scripts SQL de creación de tablas y sus respetivas columnas (BD del origen). En este módulo se generan los ficheros script SQL crear_tablas.sql y add_campos.sql (create tables y alter tables add column).
crear_inserts: Módulo que genera el fichero script SQL insert.sql, que contiene todos los INSERT INTO con la información de la tabla ó tablas pasadas como parámetro (del origen). Aquí cabe hacer mención especial a un problema de codificaciones que me he encontrado al traspasar datos de Firebird con una codificación de idioma (collate) DOS437 (tabla de códigos de MS-DOS) a SQLServer 2008. La cuestión es que había ciertos caracteres que no me los convertía bien. He estado indagando, haciendo multitud de pruebas y muchas más (cambio en chcp en MS-DOS, utf-8, iso-8859-1, encode, decode, sitecustomize y un sin fin…) y al final nada de nada. Los caracteres especiales, a saber, con tildes, ñ, Ñ, los signos de apertura de admiración e interrogación, º, ª no se codifican bien. Es como si la tabla de páginas hiciera una conversión incorrecta. ¿Solución? Crearme mi propia tabla de conversión mediante una función. He identificado los caracteres que me daban problemas y los he reemplazado (replace) por los adecuados. En la función reemplazar_caracteres(cadena) está la solución que he planteado, y funciona.
lanzadera.py: Módulo que lanza un script SQL (en el destino) que se le pasa como parámetro. Si alguna sentencia produce un error se guarda dicha sentencia SQL automáticamente en un fichero llamado error_insert.sql, y se continúa con la ejecución.
lanzar_select.py: Módulo que lanza una sentencia SQL, escrita por el usuario, contra la base de datos del origen.
Composición del proyecto y 2: Un script SQL especial.
En este proyecto hay dos scripts SQL que son lanzados desde el menú de aplicación. Uno de ellos, denominado casos_especiales_a_lanzar.sql, sirve para recoger aquellas modificaciones que necesitemos realizar después de crear las tablas de la base de datos (create tables…) y antes de la carga de los datos (inserts) sobre las tablas del destino, como por ejemplo, eliminar un campo que no necesitemos, o cambiar un tipo de dato de un campo porque nos hemos dado cuenta que la carga no la realiza correctamente, o el redondeo de un dato es erróneo (este caso puede verse, por ejemplo, en la definición del tipo de dato numeric en FireBird y en SQLServer, que es diferente para cada SGBD).
Un ejemplo del contenido de este script SQL se presenta a continuación:
ALTER TABLE ventaslineas DROP COLUMN textolibre ;
ALTER TABLE ventasalbaranes DROP COLUMN observaciones ;
ALTER TABLE articulos DROP COLUMN observaciones ;
ALTER TABLE articulos DROP COLUMN observacionesfab ;
ALTER TABLE articulos DROP COLUMN imagen ;
ALTER TABLE articulos DROP COLUMN fotografia ;
ALTER TABLE articulos DROP COLUMN stockactualimporte ;
ALTER TABLE articulos DROP COLUMN stockprevistoimporte ;
ALTER TABLE articulos DROP COLUMN stockglobalimporte ;
ALTER TABLE articulos DROP COLUMN STOCKACTUALCAJAS ;
ALTER TABLE articulos DROP COLUMN STOCKPREVISTOCAJAS ;
ALTER TABLE articulos DROP COLUMN STOCKGLOBALCAJAS ;
ALTER TABLE articulos DROP COLUMN STOCKACTUALUNIDADES ;
ALTER TABLE articulos DROP COLUMN STOCKPREVISTOUNIDADES ;
ALTER TABLE articulos DROP COLUMN STOCKGLOBALUNIDADES ;
ALTER TABLE articulos DROP COLUMN STOCKACTUALLITROSABS ;
ALTER TABLE articulos DROP COLUMN STOCKPREVISTOLITROSABS ;
ALTER TABLE articulos DROP COLUMN STOCKGLOBALLITROSABS ;
ALTER TABLE comprasalbaranes DROP COLUMN observaciones ;
ALTER TABLE COMPRASLINEAS ALTER COLUMN TIPOIVA numeric(9,3) ;
ALTER TABLE COMPRASLINEAS ALTER COLUMN LINEAALBARAN numeric(9,3) ;
ALTER TABLE COMPRASLINEAS ALTER COLUMN DESCUENTOTOTAL numeric(9,3) ;
Composición del proyecto y 3: Generación de índices de las tablas.
El segundo script SQL sirve para crear los índices de las tablas. ¿Cómo lo he solucionado? Pues he creado un script Python que obtiene los índices de las tablas a partir de un fichero script SQL que contiene el DDL de la base de datos generada por el programa DBConvert.
 Aunque esta aplicación es de pago, deja crear un cuasi traspaso entre origen y destino, creando el DDL de la base de datos, aunque no traspasa los datos (inserts sin datos reales). El truco reside en analizar el DDL mediante un script Python, y obtener la creación de índices.
Aunque esta aplicación es de pago, deja crear un cuasi traspaso entre origen y destino, creando el DDL de la base de datos, aunque no traspasa los datos (inserts sin datos reales). El truco reside en analizar el DDL mediante un script Python, y obtener la creación de índices.
Veamos este proceso con la ayuda del Management Studio de SQLServer 2008 Express Edition.

 Este script está ordenado, primero todos los create table con sus create index y luego los insert. Pues seleccionamos la parte de arriba hasta los insert, creamos otro fichero y lo guardamos ahí.
Este script está ordenado, primero todos los create table con sus create index y luego los insert. Pues seleccionamos la parte de arriba hasta los insert, creamos otro fichero y lo guardamos ahí.
 Utilizo el script obtener_indices.py para obtener los create index del fichero de la captura anterior. El resultado del script Python es un script SQL denominado indices.sql, que tiene la siguiente forma:
Utilizo el script obtener_indices.py para obtener los create index del fichero de la captura anterior. El resultado del script Python es un script SQL denominado indices.sql, que tiene la siguiente forma:
 Decir que el fichero indices.sql será lanzado desde el menú principal, mediante una función del módulo lanzadera, para crear los índices de las tablas de destino.
Decir que el fichero indices.sql será lanzado desde el menú principal, mediante una función del módulo lanzadera, para crear los índices de las tablas de destino.
El script obtener_indices.py es el siguiente:
Composición del proyecto y 4: Cambiar DOMINIOS de Firebird por el verdadero tipo de dato a traspasar a SQLServer.
Una de los con/inconvenientes que tiene FireBird es que da la posibilidad de trabajar con DOMINIOS, que son como macros de tipos de datos de campos de tablas. Está bien para definir un tipo de dato de un campo que se va a repetir en diversas tablas. El problema radica en que cuando se genera el DDL de Firebird en los create table aparecen los dominios en vez de los tipos de datos. ¿Solución? Crear un script en Python para obtener la correspondencia entre dominios y tipos de datos de FireBird a partir de su fichero DDL.
¿Cómo obtenemos el DDL del origen? Mediante FlameRobin. A continuación presento la relación de dominios del origen:
 Podemos obtener el DDL en FlameRobin desde aquí:
Podemos obtener el DDL en FlameRobin desde aquí:
La extracción del DDL la guardo en un fichero, llamado ddl_origen.sql, el cual es procesado por la función crear_diccionario() del módulo crear_tablas.py, que devuelve un diccionario de correspondencia entre dominios y sus correspondientes tipos de datos. Esto es ya más complicado, pero funciona.
Forma de uso
Creamos ficheros con script SQL para crear tablas.
 Creamos fichero script SQL con las sentencias INSERT.
Creamos fichero script SQL con las sentencias INSERT.
 Creamos tablas en destino.
Creamos tablas en destino.
 Creamos campos de las tablas en destino.
Creamos campos de las tablas en destino.
 Lanzamos script SQL con casos especiales a tratar.
Lanzamos script SQL con casos especiales a tratar.
 Creamos índices de las tablas en destino.
Creamos índices de las tablas en destino.
 Lanzamos fichero de sentencias INSERT para rellenar con datos el destino.
Lanzamos fichero de sentencias INSERT para rellenar con datos el destino.
 Ejemplos de errores que pueden ocurrir
Ejemplos de errores que pueden ocurrir
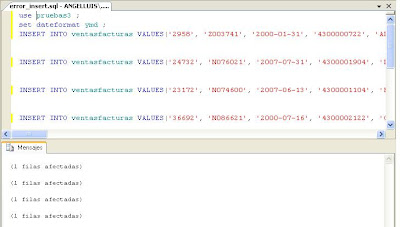
Como hemos comentado anteriormente, puede darse el caso que haya errores a la hora de ejecutar los INSERT en destino. Dichas sentencias SQL que han generado errores se llevan directamente al fichero error_insert.sql. Podemos ver el siguiente ejemplo (he cargado el script SQL en el administrador de SQLServer 2008):
 Darse cuenta que en este caso el problema reside en la fecha de la tercera columna. Los años 200 y 207 no son correctos.
Darse cuenta que en este caso el problema reside en la fecha de la tercera columna. Los años 200 y 207 no son correctos.
Lo podemos arreglar aquí mismo, y eligiendo la base de datos de destino (y si es necesario el formato de fecha con set dateformat), lanzamos obteniendo las inserciones correctas:
CÓDIGO FUENTE: TRASPASO.PY:
Creo que este artículo me ha salido enormemente largo. Con esto quiero demostrar que si no se disponen de las herramientas adecuadas para hacer un traspaso de datos, con Python puede hacerse (y seguramente con otras herramientas, incluso más fácilmente). Si hay algún navegante que necesite una guía para hacer un traspaso de datos entre FireBird y SQLServer, creo que le va a resultar de ayuda este post.
Saludos.
En este post vamos a ver cómo traspasar una base de datos, ubicada en un sistema gestor de bases de datos FireBird, a una nueva base de datos, ubicada en sistema gestor de bases de datos Microsoft SQLServer 2008 Express Edition.
Antecedentes
El origen será una base de datos FireBird con los siguientes atributos:
 (Esta información la he obtenido con FlameRobin, que es un sistema de administración para sistemas gestores de bases de datos FireBird, gratuito.)
(Esta información la he obtenido con FlameRobin, que es un sistema de administración para sistemas gestores de bases de datos FireBird, gratuito.)Primer intento de traspaso
SQLServer 2008 Express Edition tiene una herramienta de exportación/importación de datos:
 NOTA: Decir que en esta versión Express no está disponible Integration Services, en donde se realizan tareas de ETL (carga de datos). Es por ello que no la he podido utilizar, aunque aparezca en el menú de la captura.
NOTA: Decir que en esta versión Express no está disponible Integration Services, en donde se realizan tareas de ETL (carga de datos). Es por ello que no la he podido utilizar, aunque aparezca en el menú de la captura.Previamente a este paso he realizado un análisis de datos de los campos del origen, ya que no concuerdan con destino en algunos casos, y en otros no es posible asignar ciertos datos a SQLServer. Por ejemplo, la base de datos FireBird del origen (de aquí en adelante llamada origen) tiene tipos de datos Blob subtype que no tienen correspondencia con SQLServer, con lo que en el destino de la base de datos de Microsoft (destino de aquí en adelante) lo cambio por text ó ntext. Otro problema, por ejemplo, es que las tablas del origen admiten varios tipos de datos TimeStamp por tabla y en destino por cada tabla solo puede haber un TimeStamp. También hay problemas con algunas codificaciones de fechas. Aquí el destino responde bien, ya que SQLServer 2008 hace un tratamiento excelente de fechas (date) y tiempo (time), y datetime por supuesto. Muy interesante. Aquí Microsoft ha hecho un buen trabajo.
Después de un análisis de datos, en donde cambio ciertos tipos de datos, comienzo el traspaso. Las tablas más pequeñas las traspasa sin problemas, como podemos ver en la imagen:
 El problema reside en las tablas maestras, con un gran número de columnas (creo que el que diseñó la aplicación del origen no sabía mucho de normalización de bases de datos). El error que me da en las tablas se repite constantemente y es del tipo siguiente:
El problema reside en las tablas maestras, con un gran número de columnas (creo que el que diseñó la aplicación del origen no sabía mucho de normalización de bases de datos). El error que me da en las tablas se repite constantemente y es del tipo siguiente: Tanto al hacer click en “Editar asignaciones” como en “Siguiente”, me da este error:
Tanto al hacer click en “Editar asignaciones” como en “Siguiente”, me da este error: Este error parece ser que indica que no puede recorrer la tabla porque el puntero se sale del rango al recorrerla. Intento buscar más información sobre el error (que me da el propio asistente):
Este error parece ser que indica que no puede recorrer la tabla porque el puntero se sale del rango al recorrerla. Intento buscar más información sobre el error (que me da el propio asistente): Según parece no puede cargar el grid (vamos, poblar la rejilla, o como pone en el mensaje, que no puede populate).
Según parece no puede cargar el grid (vamos, poblar la rejilla, o como pone en el mensaje, que no puede populate).He buscado en Internet sobre este error. No encuentro nada que me sirva (primeros sudores fríos bajan por la mejilla).
Busco en Internet soluciones para traspasar datos específicamente desde este origen al destino dado. Hay varias opciones, pero todas de pago (cosa que no me puedo permitir) y permiten pasar unas pocas filas o no hacen todo el traspaso, como ESF Database Migration Toolkit, DBConvert for Firebird and MSSQL ó Full Convert Enterprise, Pasan 2 horas… solución… scripts Python.
Solución: Scripts Python
Hace unos días escribí un artículo sobre traspasar datos entre una FireBird y MySQL, entonces, ¿por qué no para SQLServer? Es más, tengo cierta libertad para el uso de herramientas que me ayuden a realizar el trabajo. Y el jefe quiere resultados, da igual como los obtengas (bueno, a lo mejor aquí me he pasado un poco), pero hay que dar resultados con el menor coste posible.
Lo que voy a hacer es modificar el código del script del anterior artículo, para adecuarlo al destino actual. Decir que hay que realizar modificaciones, sobretodo con respecto a los tipos de datos de los campos (tanto en el origen como en el destino). Además, ahora también se pasarán los índices de las tablas (con un pequeño truco), cosa que en el anterior post no se hacía.
¿Por dónde empezar? (Conexiones con FireBird y SQLServer 2008.)
Normalmente, salvo que seas holandés, por el principio. Lo primero, ¿cómo me conecto con el origen (FireBird)? Mediante el módulo KinterbasDB. ¿Cómo conectarse con el destino (SQLServer)? Aquí había dos opciones. La primera, el módulo pymssql. Problema: permite conectarte a SQLServer 2000, pero parece que no le gusta demasiado SQLServer 2008, así que esta opción no me sirve. Segunda, conexión por ODBC. Para ello utilizo pyodbc. Así que me creo una conexión ODBC en el Administrador de Orígenes de Datos ODBC de Windows, y luego con pyodbc creo dicha conexión en el script Python. ¡¡¡Funciona!!!. Pues me quedo con esta opción.
Composición del proyecto
¿De qué se compone mi proyecto de traspaso? De los siguientes ficheros:
traspaso.py: Fichero donde reside el menú principal para controlar las diferentes partes del traspaso de datos. Desde aquí se llaman a los demás módulos y ficheros fuente. Para ejecutar nuestra aplicación tendremos que poner python traspaso.py. Nuestra aplicación tendrá más o menos este aspecto, en IDLE:

crear_tablas.py: Módulo para crear los scripts SQL de creación de tablas y sus respetivas columnas (BD del origen). En este módulo se generan los ficheros script SQL crear_tablas.sql y add_campos.sql (create tables y alter tables add column).
crear_inserts: Módulo que genera el fichero script SQL insert.sql, que contiene todos los INSERT INTO con la información de la tabla ó tablas pasadas como parámetro (del origen). Aquí cabe hacer mención especial a un problema de codificaciones que me he encontrado al traspasar datos de Firebird con una codificación de idioma (collate) DOS437 (tabla de códigos de MS-DOS) a SQLServer 2008. La cuestión es que había ciertos caracteres que no me los convertía bien. He estado indagando, haciendo multitud de pruebas y muchas más (cambio en chcp en MS-DOS, utf-8, iso-8859-1, encode, decode, sitecustomize y un sin fin…) y al final nada de nada. Los caracteres especiales, a saber, con tildes, ñ, Ñ, los signos de apertura de admiración e interrogación, º, ª no se codifican bien. Es como si la tabla de páginas hiciera una conversión incorrecta. ¿Solución? Crearme mi propia tabla de conversión mediante una función. He identificado los caracteres que me daban problemas y los he reemplazado (replace) por los adecuados. En la función reemplazar_caracteres(cadena) está la solución que he planteado, y funciona.
lanzadera.py: Módulo que lanza un script SQL (en el destino) que se le pasa como parámetro. Si alguna sentencia produce un error se guarda dicha sentencia SQL automáticamente en un fichero llamado error_insert.sql, y se continúa con la ejecución.
lanzar_select.py: Módulo que lanza una sentencia SQL, escrita por el usuario, contra la base de datos del origen.
Composición del proyecto y 2: Un script SQL especial.
En este proyecto hay dos scripts SQL que son lanzados desde el menú de aplicación. Uno de ellos, denominado casos_especiales_a_lanzar.sql, sirve para recoger aquellas modificaciones que necesitemos realizar después de crear las tablas de la base de datos (create tables…) y antes de la carga de los datos (inserts) sobre las tablas del destino, como por ejemplo, eliminar un campo que no necesitemos, o cambiar un tipo de dato de un campo porque nos hemos dado cuenta que la carga no la realiza correctamente, o el redondeo de un dato es erróneo (este caso puede verse, por ejemplo, en la definición del tipo de dato numeric en FireBird y en SQLServer, que es diferente para cada SGBD).
Un ejemplo del contenido de este script SQL se presenta a continuación:
ALTER TABLE ventaslineas DROP COLUMN textolibre ;
ALTER TABLE ventasalbaranes DROP COLUMN observaciones ;
ALTER TABLE articulos DROP COLUMN observaciones ;
ALTER TABLE articulos DROP COLUMN observacionesfab ;
ALTER TABLE articulos DROP COLUMN imagen ;
ALTER TABLE articulos DROP COLUMN fotografia ;
ALTER TABLE articulos DROP COLUMN stockactualimporte ;
ALTER TABLE articulos DROP COLUMN stockprevistoimporte ;
ALTER TABLE articulos DROP COLUMN stockglobalimporte ;
ALTER TABLE articulos DROP COLUMN STOCKACTUALCAJAS ;
ALTER TABLE articulos DROP COLUMN STOCKPREVISTOCAJAS ;
ALTER TABLE articulos DROP COLUMN STOCKGLOBALCAJAS ;
ALTER TABLE articulos DROP COLUMN STOCKACTUALUNIDADES ;
ALTER TABLE articulos DROP COLUMN STOCKPREVISTOUNIDADES ;
ALTER TABLE articulos DROP COLUMN STOCKGLOBALUNIDADES ;
ALTER TABLE articulos DROP COLUMN STOCKACTUALLITROSABS ;
ALTER TABLE articulos DROP COLUMN STOCKPREVISTOLITROSABS ;
ALTER TABLE articulos DROP COLUMN STOCKGLOBALLITROSABS ;
ALTER TABLE comprasalbaranes DROP COLUMN observaciones ;
ALTER TABLE COMPRASLINEAS ALTER COLUMN TIPOIVA numeric(9,3) ;
ALTER TABLE COMPRASLINEAS ALTER COLUMN LINEAALBARAN numeric(9,3) ;
ALTER TABLE COMPRASLINEAS ALTER COLUMN DESCUENTOTOTAL numeric(9,3) ;
Composición del proyecto y 3: Generación de índices de las tablas.
El segundo script SQL sirve para crear los índices de las tablas. ¿Cómo lo he solucionado? Pues he creado un script Python que obtiene los índices de las tablas a partir de un fichero script SQL que contiene el DDL de la base de datos generada por el programa DBConvert.
Aunque esta aplicación es de pago, deja crear un cuasi traspaso entre origen y destino, creando el DDL de la base de datos, aunque no traspasa los datos (inserts sin datos reales). El truco reside en analizar el DDL mediante un script Python, y obtener la creación de índices.Veamos este proceso con la ayuda del Management Studio de SQLServer 2008 Express Edition.
 Este script está ordenado, primero todos los create table con sus create index y luego los insert. Pues seleccionamos la parte de arriba hasta los insert, creamos otro fichero y lo guardamos ahí.
Este script está ordenado, primero todos los create table con sus create index y luego los insert. Pues seleccionamos la parte de arriba hasta los insert, creamos otro fichero y lo guardamos ahí. Utilizo el script obtener_indices.py para obtener los create index del fichero de la captura anterior. El resultado del script Python es un script SQL denominado indices.sql, que tiene la siguiente forma:
Utilizo el script obtener_indices.py para obtener los create index del fichero de la captura anterior. El resultado del script Python es un script SQL denominado indices.sql, que tiene la siguiente forma: Decir que el fichero indices.sql será lanzado desde el menú principal, mediante una función del módulo lanzadera, para crear los índices de las tablas de destino.
Decir que el fichero indices.sql será lanzado desde el menú principal, mediante una función del módulo lanzadera, para crear los índices de las tablas de destino.El script obtener_indices.py es el siguiente:
# -*- coding: cp1252 -*-
# Programa que obtiene los índices de las tablas a partir de un fichero script SQL
# que contiene el DDL generado por el programa DBConvert.
import os
def crear_indices():
# Fichero que contiene DDL de estructura de base de datos.
fichero = 'estructura_sqlserver.sql'
fichero2 = 'indices.sql'
# Abrimos fichero de donde obtener índices.
f = open(os.path.realpath(fichero), "r")
# Creamos fichero de índices.
f1 = open(os.path.realpath(fichero2),"w")
# Vamos buscando, por cada línea, los índices.
print "Buscando índices."
while True:
# Obtenemos línea del fichero.
linea = f.readline()
if not linea:
print "Terminé de encontrar líneas en el fichero."
break
# Quitamos espacios en blanco.
linea = linea.strip()
# Comprobamos si se trata de creación de índices.
if linea[0:13] == 'CREATE INDEX':
f1.write(linea+"\n")
# Cerramos ficheros.
f.close()
f1.close()
crear_indices()
Composición del proyecto y 4: Cambiar DOMINIOS de Firebird por el verdadero tipo de dato a traspasar a SQLServer.
Una de los con/inconvenientes que tiene FireBird es que da la posibilidad de trabajar con DOMINIOS, que son como macros de tipos de datos de campos de tablas. Está bien para definir un tipo de dato de un campo que se va a repetir en diversas tablas. El problema radica en que cuando se genera el DDL de Firebird en los create table aparecen los dominios en vez de los tipos de datos. ¿Solución? Crear un script en Python para obtener la correspondencia entre dominios y tipos de datos de FireBird a partir de su fichero DDL.
¿Cómo obtenemos el DDL del origen? Mediante FlameRobin. A continuación presento la relación de dominios del origen:
 Podemos obtener el DDL en FlameRobin desde aquí:
Podemos obtener el DDL en FlameRobin desde aquí:

La extracción del DDL la guardo en un fichero, llamado ddl_origen.sql, el cual es procesado por la función crear_diccionario() del módulo crear_tablas.py, que devuelve un diccionario de correspondencia entre dominios y sus correspondientes tipos de datos. Esto es ya más complicado, pero funciona.
Forma de uso
Creamos ficheros con script SQL para crear tablas.
 Creamos fichero script SQL con las sentencias INSERT.
Creamos fichero script SQL con las sentencias INSERT. Creamos tablas en destino.
Creamos tablas en destino. Creamos campos de las tablas en destino.
Creamos campos de las tablas en destino. Lanzamos script SQL con casos especiales a tratar.
Lanzamos script SQL con casos especiales a tratar. Creamos índices de las tablas en destino.
Creamos índices de las tablas en destino. Lanzamos fichero de sentencias INSERT para rellenar con datos el destino.
Lanzamos fichero de sentencias INSERT para rellenar con datos el destino. Ejemplos de errores que pueden ocurrir
Ejemplos de errores que pueden ocurrirComo hemos comentado anteriormente, puede darse el caso que haya errores a la hora de ejecutar los INSERT en destino. Dichas sentencias SQL que han generado errores se llevan directamente al fichero error_insert.sql. Podemos ver el siguiente ejemplo (he cargado el script SQL en el administrador de SQLServer 2008):
 Darse cuenta que en este caso el problema reside en la fecha de la tercera columna. Los años 200 y 207 no son correctos.
Darse cuenta que en este caso el problema reside en la fecha de la tercera columna. Los años 200 y 207 no son correctos.Lo podemos arreglar aquí mismo, y eligiendo la base de datos de destino (y si es necesario el formato de fecha con set dateformat), lanzamos obteniendo las inserciones correctas:

CÓDIGO FUENTE: TRASPASO.PY:
CÓDIGO FUENTE: CREAR_TABLAS.PY:
# -*- coding: UTF-8 -*-
# Programa de traspaso.
import os
from crear_tablas import crear_tablas
from crear_inserts import crear_insert
from lanzadera import lanzadera
from lanzar_select import lanzar_sql
# Base de datos origen.
bd_origen = 'localhost:C:\COMPARTIDOS\MARNYS.gdb'
# Base de datos destino.
bd_destino = 'DSN=sensei_final_sqlserver;UID=MARNYS\angelluis;PWD=5558632;'
# Menú de opciones.
def menu():
# Limpiamos pantalla.
os.system("cls")
print '''
*************************************************************
* TRASPASO DE INFORMACIÓN DE FIREBIRD A SQLSERVER *
*************************************************************
'''
if len(bd_origen)!=0:
print "\t"
print "\t","\t","Origen: ", bd_origen
if len(bd_destino)!=0:
print "\t"
print "\t","\t","Destino: ", bd_destino
print '''
Elige una de las siguientes opciones:
1) Crear ficheros con creación de tablas y campos.
(Se crean crear_tablas.sql y add_campos.sql)
2) Generar sentencias INSERT a partir de nombre de tabla.
(Se crea insert.sql)
3) Lanzar manualmente sentencia SQL al origen.
-----------------------------------------------------------
4) CREAR TABLAS EN DESTINO: Lanzar crear_tablas.sql.
5) CREAR CAMPOS EN DESTINO: Lanzar add_campos.sql.
6) CREAR CASOS ESPECIALES EN DESTINO: Lanzar casos_especiales_a_lanzar.sql.
7) CREAR INDICES EN DESTINO: Lanzar crear_indices.sql.
-----------------------------------------------------------
8) INSERTAR DATOS EN DESTINO: Lanzar insert.sql.
-----------------------------------------------------------
9) (Uso futuro).
-----------------------------------------------------------
0) Salir.
Elige opción:
'''
opcion = raw_input("==> ")
return opcion
def aplicacion():
os.system('cls')
opcion = ""
while opcion != "0":
opcion = menu()
if opcion == "1":
# Creación de tablas y sus campos.
crear_tablas(bd_origen)
if opcion == "2":
# Pedimos tablas.
tablas = []
texto = ''
ret = True
while ret:
i = raw_input('(' + texto + ') ' + 'Nombre de tabla para crear inserts: ')
tablas.append(str(i))
while True:
j = raw_input('¿Incluir más tablas (S/N)?')
if j in ('S','s','SI','si','sip','SIP'):
# Información de las tablas incluidas.
texto = ''
for m in tablas:
texto = texto + m + ' '
# Salimos para insertar la siguiente tabla.
break
if j in ('N','n','NO','no','nop','NOP'):
# Salimos para no incluir más tablas.
ret = False
break
# Generación de sentencias insert.
crear_insert(bd_origen, tablas)
if opcion == "3":
lanzar_sql(bd_origen)
if opcion == "4":
# Crear tablas.
lanzadera('crear_tablas.sql', bd_destino)
if opcion == "5":
# Crear columnas.
lanzadera('add_campos.sql', bd_destino)
if opcion == "6":
# Crear casos especiales a tratar.
lanzadera('casos_especiales_a_lanzar.sql', bd_destino)
if opcion == "7":
# Crear índices.
lanzadera('crear_indices.sql', bd_destino)
if opcion == "8":
# Crear datos.
lanzadera('insert.sql', bd_destino)
i = raw_input('Pulse cualquier tecla para continuar')
# Ejecutamos el programa.
aplicacion()
CÓDIGO FUENTE: CREAR_INSERTS.PY:
# -*- coding: UTF-8 -*-
import kinterbasdb
import os
def crear_diccionario():
# Fichero que contiene DDL de estructura de base de datos.
fichero = 'ddl_sensei.sql'
# Abrimos fichero.
f = open(os.path.realpath(fichero), "r")
# Lista de correspondencia.
lista_correspondencia = []
# Vamos buscando, por cada línea, los CREATE DOMAIN.
print "Buscando dominios y su correspondencia con tipos de datos... espere."
while True:
# Obtenemos línea del fichero.
linea = f.readline()
if not linea:
print "Terminé de encontrar relaciones entre dominios y tipos de datos."
break
# Quitamos espacios en blanco.
linea = linea.strip()
# Comprobamos si se trata de creación de dominios.
if linea[0:13] == 'CREATE DOMAIN':
# Obtenemos el dominio.
dominio = linea[14:]
# Nos vamos a la siguiente línea.
linea = f.readline()
# Obtenmos el tipo de dato.
tipo_dato = linea[4:]
# Y le quitamos los espacios en blanco, por si acaso.
tipo_dato = tipo_dato.strip()
# Lo incluimos en la lista.
lista_correspondencia.append((dominio, tipo_dato))
# Cerramos fichero.
f.close()
# Convertimos la lista en un diccionario.
print "Creando tabla hashing de dominios con tipos de datos..."
diccionario = dict(lista_correspondencia)
# Y devolvemos el diccionario.
return diccionario
def crear_tablas(rutaAcceso):
# Fichero de creación de tablas y adición de campos.
fichero1 = 'crear_tablas.sql'
fichero2 = 'add_campos.sql'
# Intentamos conectar con FireBird.
try:
conexion= kinterbasdb.connect(dsn=rutaAcceso,\
user='sysdba', password='masterkey',dialect=3, charset='DOS437')
conectado = True
print "Conectado!"
except:
print "No he podido conectar con ", rutaAcceso
# Estamos conectados, a trabajar!
if conectado:
# Obtenemos todas las tablas.
cadenaSQL = '''
select rdb$relation_name
from rdb$relations
where rdb$view_blr is null
and (rdb$system_flag is null or rdb$system_flag = 0);
'''
# Inicializamos cursor.
cursor = conexion.cursor()
# Ejecutamos cursor.
cursor.execute(cadenaSQL)
# Guardamos los nombres de las tablas en una lista.
tablas = []
for fila in cursor:
tablas.append(fila[0])
print "OK!"
# Cadena que obtiene tablas con campos y tipos de datos.
cadenaSQL = '''
select rf.rdb$relation_name, rf.rdb$field_name, rf.rdb$field_source, f.rdb$field_type, t.rdb$type_name, f.rdb$field_sub_type, f.rdb$character_length, f.rdb$field_scale, f.rdb$field_length, st.rdb$type_name as rdb$sub_type_name,
case f.rdb$field_type
when 7 then 'smallint'
when 8 then 'int'
when 16 then 'int64'
when 9 then 'quad'
when 10 then 'float'
when 11 then 'd_float'
when 17 then 'boolean'
when 27 then 'decimal(16,5)'
when 12 then 'datetime'
when 13 then 'time'
when 35 then 'datetime'
when 261 then 'text'
when 37 then 'varchar'
when 14 then 'char'
when 40 then 'cstring'
when 45 then 'blob_id'
end as "ActualType",
case f.rdb$field_type
when 7 then
case f.rdb$field_sub_type
when 1 then 'numeric'
when 2 then 'decimal'
end
when 8 then
case f.rdb$field_sub_type
when 1 then 'numeric'
when 2 then 'decimal'
end
when 16 then
case f.rdb$field_sub_type
when 1 then 'numeric'
when 2 then 'decimal'
else 'float'
end
when 14 then
case f.rdb$field_sub_type
when 0 then 'unspecified'
when 1 then 'binary'
when 3 then 'acl'
else
case
when f.rdb$field_sub_type is null then 'unspecified'
end
end
when 37 then
case f.rdb$field_sub_type
when 0 then 'unspecified'
when 1 then 'text'
when 3 then 'acl'
else
case
when f.rdb$field_sub_type is null then 'unspecified'
end
end
when 261 then
case f.rdb$field_sub_type
when 0 then 'unspecified'
when 1 then 'text'
when 2 then 'blr'
when 3 then 'acl'
when 4 then 'reserved'
when 5 then 'encoded-meta-data'
when 6 then 'irregular-finished-multi-db-tx'
when 7 then 'transactional_description'
when 8 then 'external_file_description'
end
end as "ActualSubType"
from rdb$relation_fields rf
join rdb$fields f
on f.rdb$field_name = rf.rdb$field_source
left join rdb$types t
on t.rdb$type = f.rdb$field_type
and t.rdb$field_name = 'RDB$FIELD_TYPE'
left join rdb$types st
on st.rdb$type = f.rdb$field_sub_type
and st.rdb$field_name = 'RDB$FIELD_SUB_TYPE'
where rf.rdb$view_context is null
and (rf.rdb$system_flag is null or rf.rdb$system_flag = 0)
order by
rf.rdb$relation_name,
rf.rdb$field_position ;
'''
# Inicializamos cursor.
cursor.close()
cursor = conexion.cursor()
# Info.
print "Recuperando información de campos de tablas!"
# Ejecutamos cursor.
cursor.execute(cadenaSQL)
# Guardamos los nombres de las tablas en una lista.
campos_tablas = []
# Creamos diccionario con correspondencia entre dominios y tipos de datos.
tabla_hash = crear_diccionario()
# Posiciones: 0 nombre tabla, 1 nombre campo, 2 dominio, 8 longitud del campo, 10 tipo dato, 11 subtipo dato.
print "Asignando tipos de datos"
for fila in cursor:
dominio_aux = str(fila[2]).strip()
# Miramos si hay un dominio.
try:
# Buscamos correspondencia entre el dominio y el tipo de dato.
tipo_dato_aux = tabla_hash[dominio_aux]
# Quitamos espacios en blanco.
tipo_dato_aux = tipo_dato_aux.strip()
# Realizamos algunos cambios de tipo.
if tipo_dato_aux == 'Timestamp':
tipo_dato_aux = 'datetime'
if tipo_dato_aux[0:4] == 'Blob':
tipo_dato_aux = 'text'
if tipo_dato_aux == 'bigint':
tipo_dato_aux = 'float'
# Hay un dominio, por lo que se incluye el tipo de dato asociado.
campos_tablas.append((fila[0],fila[1],tipo_dato_aux,0,0))
except:
# No hay dominio, hay que obtener el tipo de dato de otros campos.
# Hay que mirar primero si tiene subtipo. Si existe, se toma ese valor.
if (fila[11] != None) and str(fila[11]).strip() != 'unspecified':
campos_tablas.append((fila[0],fila[1],fila[8],fila[11],1))
else:
campos_tablas.append((fila[0],fila[1],fila[8],fila[10],1))
# Info.
print "OK!"
print "Guardando información en ficheros SQL!"
# Creamos fichero.
f = open(os.path.realpath(fichero1), "w")
# Creamos los create table.
for tabla in tablas:
cadenaSQL = 'CREATE TABLE ' + str(tabla).strip() +' ( marnys char(1) ) ;'
f.write(cadenaSQL+"\n")
# Cerramos fichero.
f.close()
# Creamos fichero.
f2 = open(os.path.realpath(fichero2), "w")
# Creamos alter table.
for campo in campos_tablas:
if str(campo[4]) == '0':
dato_aux = str(campo[2]).strip()
if dato_aux == 'numeric(8)':
dato_aux = 'numeric(15,2)'
cadenaSQL = 'ALTER TABLE ' + str(campo[0]).strip() + ' ADD ' + str(campo[1]).strip() + \
' ' + dato_aux + ' ;'
if str(campo[4]) == '1':
dato_aux = str(campo[3]).strip()
if dato_aux == 'datetime' or \
dato_aux == 'int' or \
dato_aux == 'smallint' or \
dato_aux == 'float' or \
dato_aux == 'ntext' or \
dato_aux == 'text' or \
dato_aux == 'decimal(16,5)' or \
dato_aux == 'numeric' or \
dato_aux == 'time':
if dato_aux == 'numeric':
dato_aux = 'numeric(15,2)'
cadenaSQL = 'ALTER TABLE ' + str(campo[0]).strip() + ' ADD ' + str(campo[1]).strip() + \
' ' + dato_aux + ' ;'
else:
cadenaSQL = 'ALTER TABLE ' + str(campo[0]).strip() + ' ADD ' + str(campo[1]).strip() + \
' ' + str(campo[3]).strip() + '(' + str(campo[2]).strip()+ ') ;'
f2.write(cadenaSQL+"\n")
# Eliminamos el campo testigo 'marnys'.
for tabla in tablas:
cadenaSQL = 'ALTER TABLE ' + tabla + ' DROP COLUMN marnys ; '
f2.write(cadenaSQL+"\n")
# Cerramos fichero.
f2.close()
# Info.
print "Terminada exportación de datos!"
# Cerramos conexiones de cursor y base de datos.
print "Cerrando conexiones!"
cursor.close()
conexion.close()
CÓDIGO FUENTE: LANZAR_SELECT.PY:
# -*- coding: UTF-8 -*-
import kinterbasdb
import os
def reemplazar_caracteres(cadena):
cadena = str(cadena)
# Reemplazamos \ por /.
cadena = cadena.replace('\\','/')
# Quitamos comillas dobles.
cadena = cadena.replace('"','')
# Quitamos comillas simples.
cadena = cadena.replace("'","")
# Quitamos caracteres extraños.
# á
cadena = cadena.replace(u'\xdf',u'\xE1')
# é
cadena = cadena.replace(u'\u0398',u'\xE9')
# í
cadena = cadena.replace(u'\u03c6',u'\xED')
# ó
cadena = cadena.replace(u'\u2264',u'\xF3')
# ú
cadena = cadena.replace(u'\xb7',u'\xFA')
# Á
cadena = cadena.replace(u'\u2534',u'\Xc1')
# É
cadena = cadena.replace(u'\u2554',u'\xC9')
# Í
cadena = cadena.replace(u'\u2550',u'\xcd')
# Ó
cadena = cadena.replace(u'\u2559',u'\Xd3')
# Ú
cadena = cadena.replace(u'\u250c',u'\xda')
# ñ
cadena = cadena.replace(u'\xb1',u'\xF1')
# Ñ
cadena = cadena.replace(u'\u2564',u'\xD1')
# º
cadena = cadena.replace(u'\u2551',u'\xBA')
# ª
cadena = cadena.replace(u'\xac',u'\xAA')
# ¿
cadena = cadena.replace(u'\u2510',u'\xBF')
# ¡
cadena = cadena.replace(u'\xed',u'\xA1')
# Ü
cadena = cadena.replace(u'\u2584',u'\xDC')
# ü
cadena = cadena.replace(u'\u207f',u'\xFC')
# Acento ´
cadena = cadena.replace(u'\u2524',u'\xb4')
# Devolvemos cadena.
return cadena
def caso_especial(tabla_a_tratar):
if tabla_a_tratar == 'articulos':
# Se hace select de todo excepto de campo observaciones, imagen, fotografia, stockactualimporte
# stockprevistoimporte, stockglobalimporte,STOCKACTUALCAJAS, STOCKPREVISTOCAJAS,
# STOCKGLOBALCAJAS, STOCKACTUALUNIDADES, STOCKPREVISTOUNIDADES, STOCKGLOBALUNIDADES,
# STOCKACTUALLITROSABS, STOCKPREVISTOLITROSABS, STOCKGLOBALLITROSABS, y observacionesfab:
sentenciaSelect = '''
SELECT ARTICULO, TITULO, TITULOTPV, CUENTAPROVEEDOR, FAMILIA, FECHAALTA, IVA, COMISION,
TIPO, EXISTENCIASMINIMAS, EXISTENCIASMAXIMAS, PEDIDOMINIMOCOMPRAS, PEDIDOMINIMOVENTAS,
FABRICACIONMINIMA, DIASRETARDORECEPCION, ARTICULOEQUIVALENTE, ARTICULOPROVEEDOR, PESO,
VOLUMEN, LARGO, ANCHO, ALTO, FACTORUDSCOMPRA, FACTORUDSVENTA, FACTORCONVERSION,
UNIDADESCAJA, NAVE, CALLE, PASILLO, ESTANTERIA, ALTURA, FECHAULTIMACOMPRA,
PRECIOULTIMACOMPRA, FECHAULTIMAVENTA, PRECIOULTIMAVENTA, PRECIOULTIMAFABRICACION,
FECHAULTIMAFABRICACION, STOCKINICIALUNIDADES, STOCKINICIALCAJAS, STOCKINICIALIMPORTE,
COMPRASUNIDADES, COMPRASCAJAS, COMPRASIMPORTE, ENTRADASUNIDADES, ENTRADASCAJAS,
ENTRADASIMPORTE, FABRICADASUNIDADES, FABRICADASCAJAS, FABRICADASIMPORTE,
VENTASUNIDADES, VENTASCAJAS, VENTASIMPORTE, SALIDASUNIDADES, SALIDASCAJAS,
SALIDASIMPORTE, ENVIADASFABRICARUNIDADES, ENVIADASFABRICARCAJAS, ENVIADASFABRICARIMPORTE,
PDTEFABRICARUNIDADES, PDTEFABRICARCAJAS, PDTEFABRICARIMPORTE, RESERVADASFABRICACIONUNIDADES,
RESERVADASFABRICACIONCAJAS, RESERVADASFABRICACIONIMPORTE, PDTERECIBIRUNIDADES,
PDTERECIBIRCAJAS, PDTERECIBIRIMPORTE, PDTESERVIRUNIDADES, PDTESERVIRCAJAS, PDTESERVIRIMPORTE,
NIVEL, SECCION, UNIDADESPORHORA, AGENTESCOMISPORC, AGENTESCOMISEUROS,
PRECIOMEDIO, STOCKACTUALIMPORTEPUC, STOCKACTUALIMPORTEPM,
PRECIORECOMANDADO, COSTECONDCOMPRA, SENSINC,
SENSINCTERMINAL, FECHAUMOD, GRADUACIONALCOHOLICA, LITROS, IMPALCOHOLPENINSULA,
IMPALCOHOLCANARIAS, IMPALCOHOLCEUTAMELI, AFECTOACUENTAUBES, AUV_CODIGOPSION,
AUV_NOVENTA, AUV_PERMITENEGATIVOS, AUV_MODIFICARPRECIO, BO_PRIMERAMATERIA,
BO_PRODUCTOTERMINADO, BO_PRECINTAS, BO_MODELOPRECINTA, BO_MODELO500, BO_MODELO557,
BO_MODELO563, MODIFICADOEUROLUX, COLOR, COMPRASLITROSABS, ENTRADASLITROSABS,
ENVIADASFABRICARLITROSABS, FABRICADASLITROSABS, PDTEFABRICARLITROSABS, PDTERECIBIRLITROSABS,
PDTESERVIRLITROSABS, RESERVADASFABRICACIONLITROSABS, SALIDASLITROSABS, STOCKINICIALLITROSABS,
UNIDADESLITROSABS, VENTASLITROSABS, CONOBSCONDCOMPRA, PAQUETESPALET, CAJASPAQUETE, TIPODESECHO,
GASTOSULTIMOPRECIO, GASTOSIMPORTETOTAL, PRECIOMEDIOCONGASTOS, MERMAUNIDADES, MERMALITROS,
MERMACAJAS, DIASRETRASOINTERNO, OBJETO, MARCA, MODELO, ROTACIONSTOCKMINIMO,
ROTACIONSTOCKMAXIMO, PVPPUNTOVERDE, GRUPO, BO_PRIMERAMATERIADATA,
BO_PRODUCTOTERMINADODATA, BO_EMBOTELLADOSCARGO, BO_EMBOTELLADOSDATA, BO_PRECINTASDATA,
FABRICACIONAUTOMATICA, INACTIVO, GASTOSULTIMOIMPORTE, MATERIAPELIGROSA,
ANIOCADUCIDAD, PARTIDAINTRASAT, COMISIONIMPORTEUNIDADES, UNIDADESNOSTOCKABLES, FUA,
FUM, MARGENCALCULODESGLOSE1, MARGENCALCULODESGLOSE2, MESESCADUCIDAD, DIASCADUCIDAD, CRUCEREFERENCIAS
FROM ARTICULOS
'''
if tabla_a_tratar == 'ventaslineas':
# Se hace select de todo excepto del campo textolibre.
sentenciaSelect = '''
SELECT LINEA, ENLACEALBARAN, ENLACETICKET, LINEAALBARAN, TERMINALPUNTOVENTA, ARTICULO,
TITULO, CODIGOBARRAS, COMENTARIO, ALMACEN, LOTEEXPEDICION, LOTEFECHACADUCIDAD,
UNIDADDEMEDIDA, CANTIDAD, LARGO, ANCHO, ALTO, USARCANTIDAD, USARPESO, UNIDADES,
CAJAS, BULTOS, TARIFA, TARIFAPRECIO, TARIFATIPO, TARIFAUNIDADES, UNIDADESADESCONTAR,
VOLUMEN, PESO, PVPPUNTOVERDE, PRECIO, UNIDADESIMPORTE, BASEIMPONIBLEBRUTA, DESCUENTO1,
DESCUENTO2, DESCUENTO3, DESCUENTO4, DESCUENTOTOTAL, IMPORTEDESCUENTO, BASEIMPONIBLE,
DESCUENTOCABECERA, IMPORTEDESCUENTOCAB, TIPOIVA, CUOTAIVA, TIPORECARGO, CUOTARECARGO,
IMPORTE, CENTRODECOSTES, IMPORTEPUNTOVERDE, VENDEDOR1, COMISIONVENDEDOR1, VENDEDOR2,
COMISIONVENDEDOR2, PORTESIMPORTE, PRECIOULTIMACOMPRA, PRECIOMEDIO,
BENEFICIOAPRECIOULTIMACOMPRA, BENEFICIOPRECIOPRECIOMEDIO, USUARIOCREADOR, FECHACREACION,
FECHAULTIMAMODIFICACION, PEDIDOCLIENTE, PEDIDOCLIENTEFECHA, HISAMON, PEDIDO, TRABAJADOR,
MAQUINA, OBRA, CAPITULO, PRESUPUESTO, CEBADERO, USUARIOTPV, ORDENEXTERNO, SENSINC,
SENSINCTERMINAL, FECHAUMOD, PROMOCIONESPROMOCION, PROMOCIONESTIPO, PROMOCIONESUNIDADES,
PROMOCIONESUNIDADESDEVENTA, PROMOCIONESUNIDADESAREGALAR, GRADUACIONALCOHOLICA, LITROS,
IMPUESTOESPECIALPRECIO, IMPUESTOESPECIALTIPO, USARLITROS, IMPUESTOESPECIALCUOTA, LITROSABS,
SECCION, UBICACIONMAQUINA, CONTROLPAQUETE, CONTROLPALET, CONTROLCAJA, CONTROLUNIDAD,
VENDEDOR3, COMISIONVENDEDOR3, RAPPELSPORCIENTOFUERAFTA, RAPPELSIMPORTEFUERAFTA, DIV_PRECIO,
DIV_BASEIMPONIBLEBRUTA, DIV_IMPORTEDESCUENTO, DIV_BASEIMPONIBLE, DIV_IMPORTEDESCUENTOCAB,
DIV_CUOTAIVA, DIV_CUOTARECARGO, DIV_IMPORTE, DIV_PORTESIMPORTE, TITULOIDIOMA,
ENLACEVENTASPEDIDOSLINEAS, UNIDADDEINTRODUCCION, UNIDADESDEINTRODUCCION, PRECIOULTIMAFABRICACION,
ARTICULOCLIENTE, PESOBRUTO, TARA, AUV_MARCADO, ENLACEORDENDEFINITIVA, ENLACEFABRICACION,
PROMOCIONESENLACELINEA, TASASENLACELINEA, CENTROCOSTE, ASTA, HUMEDAD, CENIZASTOTALES,
CENIZASINSOLUBLES, AFLATOXINAS, OCHRATOXINAS, OMEGOTRAS1, OMEGOTRAS2, OMEGOTRAS3, OMEGOTRAS4,
OMEGOTRAS5, LOTEALMACEN, NUMERADORPARTIDA, NUMERADORCOMPONENTE, NUMERADORUTILLAJE,
USARPESOUNIDADES, STOCKABLE, VALORPUNTOCLIENTE, PRECIOTARIFA, PORCENTAJEBENPUC, GASTOSIMPORTE,
GASTOSIMPORTEAPLICABLE, BLOQUEARLINEA, NOAPLICARDCTO, ARTICULOENVASE
FROM VENTASLINEAS
'''
if tabla_a_tratar == 'ventasalbaranes':
# Se hace select de todo excepto del campo observaciones.
sentenciaSelect = '''
SELECT ALBARAN, SERIEALBARAN, ENLACEFACTURA, FECHAALBARAN, CLIENTE, CLIENTENOMBRE, CLIENTEDNI,
CLIENTEDIRECCION, CLIENTEPOBLACION, CLIENTECODIGOPOSTAL, CLIENTETELEFONO1, CLIENTETELEFONO2,
ENVIARNOMBRE, ENVIARALAATENCION, ENVIARDNI, ENVIARDIRECCION, ENVIARPOBLACION, ENVIARCODIGOPOSTAL,
ENVIARTELEFONO1, ENVIARTELEFONO2, VENDEDOR, COMISION, AGENCIA, INDICEDOCUMENTO, TEXTO1, TEXTO2,
TEXTO3, TEXTO4, TEXTO5, DIVISA, FECHACAMBIO, CAMBIO, IDIOMA, TOTALVOLUMEN,
TOTALPESO, TOTALBULTOS, TOTALCAJAS, TOTALBASEIMPONIBLEBRUTA, TOTALIMPORTEDESCUENTO,
TOTALIMPORTECUOTAIVA, TOTALIMPORTECUOTARECARGO, DESCUENTOCOMERCIAL, IMPORTEDESCUENTOCOMERCIAL,
AJUSTARA, DIFERENCIACALCULO, TOTALPARCIAL, TOTALIMPORTEPUNTOVERDE, PORTESTIPO, PORTESBASEIMPONIBLE,
PORTESTIPOIVA, PORTESIMPORTEIVA, PORTESIMPORTE, RETENERSOBRE, TIPORETENCION, RETENCION, SUPLIDOS,
COBRADOACUENTA, IMPORTETOTALDOCUMENTO, BENEFICIOAPRECIOMEDIO, BENEFICIOAPRECIOULTIMACOMPRA,
FORMADEPAGO, DOCUMENTOPAGO, TIPODOCUMENTO, BANCOPARATRANSFERIR, ALBARANIMPRESO, RECIBOSIMPRESO,
MODELOIMPRESO, REGISTROMSDOS, USUARIOCREADOR, FECHACREACION, FECHAULTIMAMODIFICACION, ORDENDIRENVIO,
ORDENEXTERNO, SENSINC, SENSINCTERMINAL, FECHAUMOD, CAEREMITENTE, CAEPROPIO, NMOD500,
PORTESTIPORECARGO, PORTESIMPORTERECARGO, TOTALLITROSABS, SUBEMPRESA, HORAINICIO, HORAFIN,
DIV_TOTALBASEIMPONIBLEBRUTA, DIV_TOTALIMPORTEDESCUENTO, DIV_TOTALIMPORTECUOTAIVA,
DIV_TOTALIMPORTECUOTARECARGO, DIV_IMPORTEDESCUENTOCOMERCIAL, DIV_AJUSTARA, DIV_TOTALPARCIAL,
DIV_PORTESBASEIMPONIBLE, DIV_PORTESIMPORTEIVA, DIV_PORTESIMPORTERECARGO, DIV_PORTESIMPORTE,
DIV_RETENCION, DIV_SUPLIDOS, DIV_COBRADOACUENTA, DIV_IMPORTETOTALDOCUMENTO, CEMENVIAR, CEMCAMION,
CEMREMOLQUE, CEMCONDUCTOR, CEMDNI, COBROSLIBRES, PERIODIFICACION, ENVIARNOMBREDIRECCION,
MATERIAPELIGROSA, ENVIARBANCO, ENVIARBANCO_DIRECCION, ENVIARBANCO_POBLACION, ENVIARBANCO_CODIGOPOSTAL,
ENVIARBANCO_CUENTACORRIENTE, FACTURACIONAUTOMATICA, PESOGLOBAL, DECIROMPEDIDO, PAPILIOPEDIDO,
FECHAEXPORTACION, ENVIARTIPOIVA, MARCATEMPORAL, BANCODECOBRO, GASTOSIMPORTE, AUTORIZADOPOR,
BLOQUEARALBARAN, ENVIARDEPARTAMENTO, NUMMATRICULA, NUMPC, COMPRAGENERADO, NUMERADOROBRA,
NUMERADORCAPITULO, OPERADORTRANSPORTE
FROM VENTASALBARANES
'''
if tabla_a_tratar == 'comprasalbaranes':
# Todo excepto campo observaciones.
sentenciaSelect = '''
SELECT ALBARAN, SERIEALBARAN, SERIEALBARANPROVEEDOR, ENLACEFACTURA, FECHAALBARAN, PROVEEDOR,
PROVEEDORNOMBRE, PROVEEDORDNI, PROVEEDORDIRECCION, PROVEEDORPOBLACION, PROVEEDORCODIGOPOSTAL,
PROVEEDORTELEFONO1, PROVEEDORTELEFONO2, VENDEDOR, COMISION, AGENCIA, INDICEDOCUMENTO, TEXTO1,
TEXTO2, TEXTO3, TEXTO4, TEXTO5, DIVISA, FECHACAMBIO, CAMBIO, IDIOMA,
TOTALVOLUMEN, TOTALPESO, TOTALBULTOS, TOTALCAJAS, TOTALBASEIMPONIBLEBRUTA, TOTALIMPORTEDESCUENTO,
TOTALIMPORTECUOTAIVA, TOTALIMPORTECUOTARECARGO, DESCUENTOCOMERCIAL, IMPORTEDESCUENTOCOMERCIAL,
AJUSTARA, DIFERENCIACALCULO, TOTALPARCIAL, TOTALIMPORTEPUNTOVERDE, PORTESTIPO, PORTESBASEIMPONIBLE,
PORTESTIPOIVA, PORTESIMPORTEIVA, PORTESIMPORTE, RETENERSOBRE, TIPORETENCION, RETENCION, SUPLIDOS,
COBRADOACUENTA, IMPORTETOTALDOCUMENTO, COSTEAPRECIOMEDIO, COSTEAPRECIOULTIMACOMPRA, FORMADEPAGO,
DOCUMENTOPAGO, TIPODOCUMENTO, BANCOPARATRANSFERIR, ALBARANIMPRESO, REGISTROMSDOS, USUARIOCREADOR,
FECHACREACION, FECHAULTIMAMODIFICACION, ORDENEXTERNO, SENSINC, SENSINCTERMINAL, FECHAUMOD,
CAEREMITENTE, CAEPROPIO, NMOD500, TOTALLITROSABS, SUBEMPRESA, GASTOSIMPORTETOTAL, NUMERADOROBRA,
NUMERADORCAPITULO, NUMERADORPARTIDA, NUMERADORCOMPONENTE, NUMERADORUTILLAJE, BLOQUEARALBARAN
FROM COMPRASALBARANES
'''
return sentenciaSelect
def crear_insert(rutaAcceso, tablas_a_tratar):
# Info.
print "Carga de datos en el sistema cliente"
# Fichero de carga de datos mediante insert.
fichero1 = 'insert.sql'
# Inicializamos testigo.
conectado = False
# Intentamos conectar con FireBird.
try:
conexion= kinterbasdb.connect(dsn=rutaAcceso,\
user='sysdba', password='masterkey',dialect=3, charset='DOS437')
conectado = True
print "Conectado con FireBird!"
except:
print "No he podido conectar con ", rutaAcceso
# Estamos conectados, a trabajar!
if conectado:
# Obtenemos todas las tablas.
cadenaSQL = '''
select rdb$relation_name
from rdb$relations
where rdb$view_blr is null
and (rdb$system_flag is null or rdb$system_flag = 0);
'''
# Inicializamos cursor.
cursor = conexion.cursor()
print "Recuperando nombres de tablas....!"
# Ejecutamos cursor.
cursor.execute(cadenaSQL)
# Guardamos los nombres de las tablas en una lista.
tablas = []
tablas = tablas_a_tratar
print "OK!"
# Creamos fichero de script en donde se guardarán los insert.
f3 = open(os.path.realpath(fichero1), "w")
# Info.
print "Generando sentencias INSERT para volcado de datos."
# Vamos obteniendo información por cada tabla para generar sentencias SQL INSERT.
for tabla in tablas:
# info.
print "Formando los INSERT para tabla ", tabla
# Tabla actual a tratar.
tabla_actual = tabla
# Info.
print "Recuperando información... esta operación puede tardar..."
# Obtenemos todas las filas de la tabla.
if tabla_actual.lower() == 'ventaslineas' or \
tabla_actual.lower() == 'ventasalbaranes' or \
tabla_actual.lower() == 'articulos' or \
tabla_actual.lower() == 'comprasalbaranes':
sentenciaSelect = caso_especial(tabla_actual.lower())
else:
sentenciaSelect = "select * from "
cursor.execute(sentenciaSelect + " " + tabla_actual)
aux = cursor.fetchall()
# Info.
print "Formando sentencias INSERT y guardándolas en fichero script... un momento..."
# Incluimos formato de fecha.
cadenaSQL = 'SET DATEFORMAT ymd ;'
f3.write(cadenaSQL+"\n")
# Para cada fila, vamos obteniendo la información para construir las INSERT.
for i in aux:
cadenaSQL = 'INSERT INTO ' + tabla_actual + ' VALUES('
aux2 = ''
for j in i:
if len(str(j)) > 2000:
j = 'DATOS NO CARGADOS'
print "Cadena demasiada larga, no se guardará!"
try:
j = reemplazar_caracteres(j)
except:
print "He tenido problemas en algunas codificaciones. Me ha dado problemas la siguiente cadena:"
print j
print "Prosigo con el análisis de datos..."
if aux2 == '':
aux2 = 'null' if j == 'None' else "'" + str(j) + "'"
else:
k = 'null' if str(j) == 'None' else "'" + str(j) + "'"
aux2 = str(aux2) + ', ' + k
cadenaSQL = str(cadenaSQL) + str(aux2) + ') ;'
f3.write(cadenaSQL+"\n")
# Cerramos fichero.
f3.close()
# Cerramos conexiones de cursor y base de datos.
print "Cerrando conexiones de FireBird!"
cursor.close()
conexion.close()
CÓDIGO FUENTE: LANZADERA.PY:
# -*- coding: UTF-8 -*-
import kinterbasdb
import os
# Obtenemos el total de filas de todas las tablas.
def lanzar_sql(rutaAcceso):
conectado= False
# Intentamos conectar con FireBird.
try:
conexion= kinterbasdb.connect(dsn=rutaAcceso,\
user='sysdba', password='masterkey',dialect=3, charset='DOS437')
conectado = True
print "Conectado!"
except:
print "No he podido conectar con ", rutaAcceso
# Estamos conectados, a trabajar!
if conectado:
# Obtenemos todas las tablas.
i = raw_input("SENTENCIA SQL A LANZAR: ")
cadenaSQL = str(i).strip()
# Inicializamos cursor.
cursor = conexion.cursor()
# Ejecutamos cursor.
cursor.execute(cadenaSQL)
filas = cursor.fetchall()
for fila in filas:
print fila
# Cerramos conexiones de cursor y base de datos.
cursor.close()
conexion.close()
CONCLUSIONES
# -*- coding: UTF-8 -*-
import pyodbc
import os
import codecs
def lanzadera(fichero_script_sql,conexionDestinoOdbc):
# Info.
print "Lanzadera de sentencias SQL."
# Fichero de errores que aparecen en la carga.
fichero_error = 'error_insert.sql'
# Inicializamos testigo.
conectado = False
# Intentamos conectar con sistema gestor cliente (por ahora SQLServer).
try:
conexionSQLServer = pyodbc.connect(conexionDestinoOdbc)
cursorSQLServer = conexionSQLServer.cursor()
conectado = True
print "Conectado con SQLServer!"
except:
print "No he podido conectar con base de datos SQLServer!"
# Estamos conectados, a trabajar!
if conectado:
# Abrimos fichero de sentencias SQL.
f = codecs.open(fichero_script_sql,'r','utf-8')
#f = open(os.path.realpath(fichero_script_sql),'r')
# Abrimos fichero de posibles errores.
f1 = open(os.path.realpath(fichero_error),'w')
# Ejecutamos sentencia SQL, por cada línea.
while True:
# Línea de fichero.
cadenaSQL = f.readline()
if not cadenaSQL:
print "TERMINÉ DE LANZAR SENTENCIAS SQL. SALIENDO DEL SCRIPT DE PYTHON!!!"
break
try:
# Lanzamos Sentencia.
cursorSQLServer.execute(cadenaSQL)
# Confirmamos escritura.
conexionSQLServer.commit()
except:
# Hubo un error, se informa en el fichero de errores y se continúa.
conexionSQLServer.rollback()
# info.
print "Hubo un error en la instrucción: ", cadenaSQL
print "Guardando fallo en fichero!"
f1.write(cadenaSQL + "\n")
# Cerramos fichero.
f.close()
f1.close()
# Cerramos conexiones de cursor y base de datos.
print "Cerrando conexiones de SQLServer!"
cursorSQLServer.close()
conexionSQLServer.close()
Creo que este artículo me ha salido enormemente largo. Con esto quiero demostrar que si no se disponen de las herramientas adecuadas para hacer un traspaso de datos, con Python puede hacerse (y seguramente con otras herramientas, incluso más fácilmente). Si hay algún navegante que necesite una guía para hacer un traspaso de datos entre FireBird y SQLServer, creo que le va a resultar de ayuda este post.
Saludos.


Thanks for every other fantastic post. Where else may just anyone
ResponderEliminarget that type of information in such an ideal approach of writing?
I have a presentation subsequent week, and I am at the search for
such information.
My web page; declaring bankruptcy in florida